

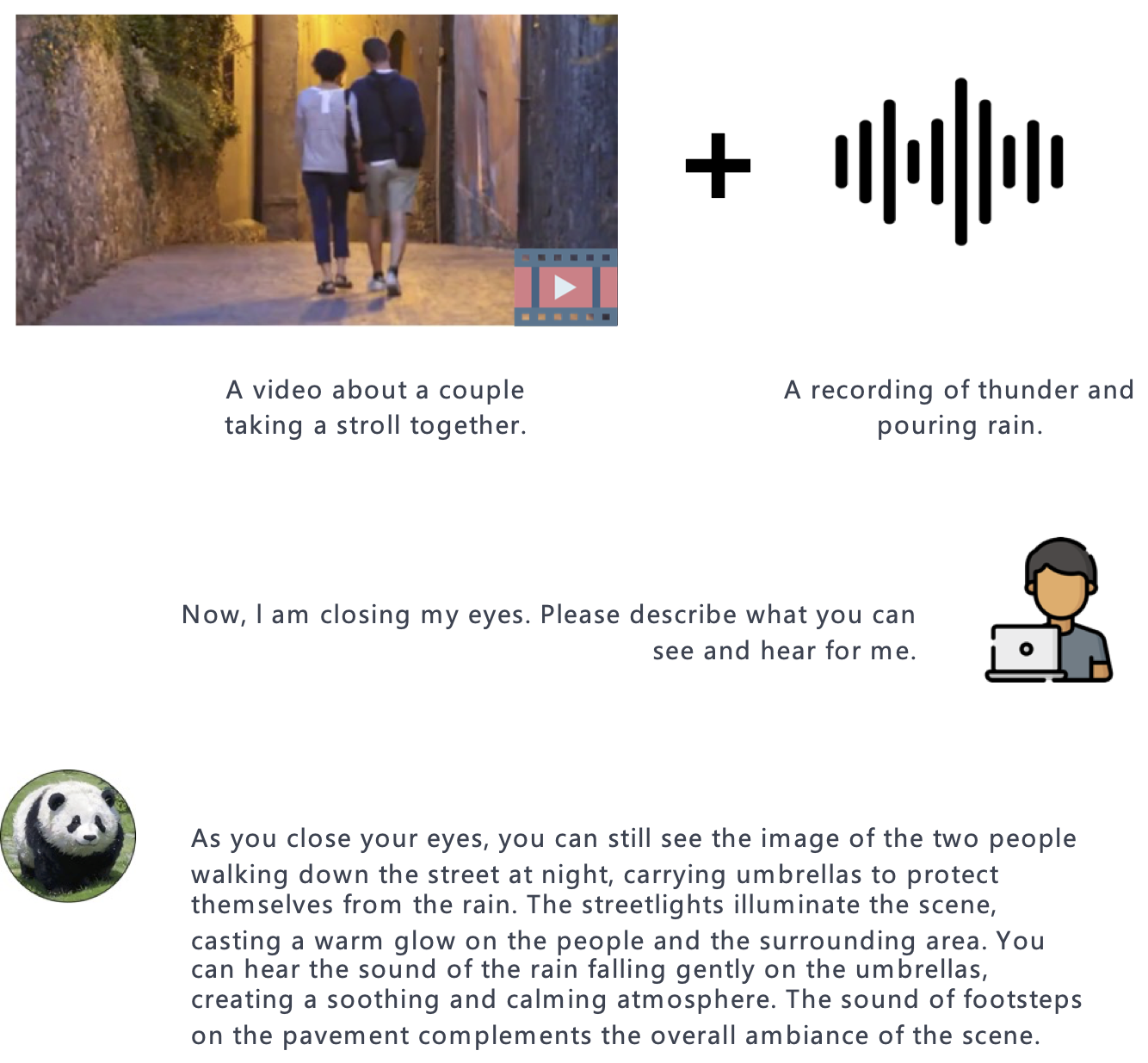





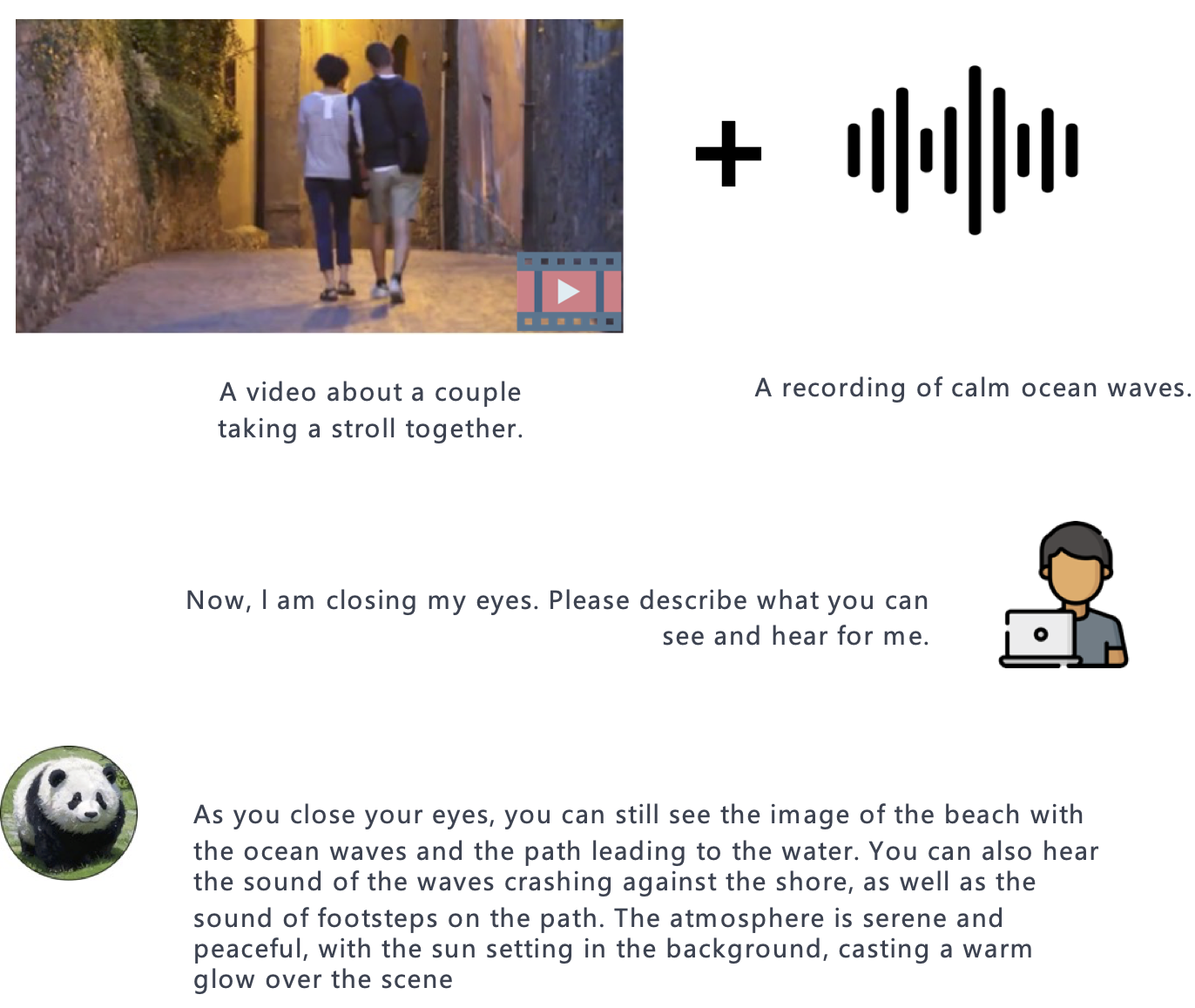


PandaGPT is a general-purpose instruction-following model that can both see and hear. Our pilot experiments show that PandaGPT can perform complex tasks such as detailed image description generation, writing stories inspired by videos, and answering questions about audios. More Interestingly, PandaGPT can take multimodal inputs simultaneously and compose their semantics naturally. For example, PandaGPT can connect how objects look in a photo and how they sound in an audio. To do so, PandaGPT combines the multimodal encoders from ImageBind and the large language models from Vicuna. Notably, though PandaGPT demonstrates impressive cross-modal capabilities across six modalities (text, image/video, audio, depth, thermal, and IMU), it is only trained with aligned image-text pairs, thanks to the the shared embedding space provided by ImageBind. We hope that PandaGPT serves as an initial step toward building AGI that can perceive and understand inputs in different modalities holistically, as we humans do.
PandaGPT combines the multimodal encoders from ImageBind and the large language models from Vicuna, achieving impressive capabilities across six modalities (text, image/video, audio, depth, thermal, and IMU). Notably the current version of PandaGPT is only trained with aligned image-text pairs (160k image-language instruction-following data released by LLaVa and Mini-GPT4), with a small set of new parameters introduced:
The architecture of PandaGPT.
Compared to existing multimodal instruction-following models trained individually for one particular modality, PandaGPT can understand and combine information in different forms together, including text, image/video, audio, depth (3D), thermal (infrared radiation), and inertial measurement units (IMU). We find that the capabilities of PandaGPT include but are not limited to (with examples attached in the bottom of this page):
@article{su2023pandagpt,
title={PandaGPT: One Model To Instruction-Follow Them All},
author={Su, Yixuan and Lan, Tian and Li, Huayang and Xu, Jialu and Wang, Yan and Cai, Deng},
journal={arXiv preprint arXiv:2305.16355},
year={2023}
}
This website template is borrowed from the MiniGPT-4 project, which is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.